
Comandi avanzati Linux
Ormai hai una certa familiarità con molti comandi e con il loro output e questo mi permette di parlarti dell'I/O (input/output).
stdin, stdout e stderr
Eseguiamo il seguente comando e discutiamo come funziona.
$ echo Salve professor Falken> saluto.txt
Che cosa è successo? Controlla la directory dove hai eseguito il comando, dovresti vedere un file chiamato saluto.txt, dentro quel file dovresti vedere il testo Salve professor Falken. Con un singolo comando sono successe diverse cose, quindi analizziamo.
Per prima cosa analizziamo la prima parte:
$ echo Salve professor Falken
Sappiamo che questo stampa Salve professor Falken sullo schermo, ma in che modo? I processi utilizzano i flussi di I/O per ricevere l'ingresso e l'uscita. Per default il comando echo prende l'input (input standard o stdin) dalla tastiera e restituisce l'output (output standard o stdout) allo schermo. Ecco perché quando si digita echo Salve professor Falken nella propria shell, si ottiene la parola sullo schermo. Tuttavia il reindirizzamento I/O ci permette di cambiare questo comportamento predefinito dandoci una maggiore flessibilità del file.
Il > è un operatore di reindirizzamento che ci permette di cambiare la direzione dell'uscita standard. Ci permette di inviare l'uscita su un file, nell'esempio, invece che sullo schermo. Se il file non esiste, verrà creato. Tuttavia, se esiste, lo sovrascriverà (è possibile aggiungere un flag per evitare che ciò avvenga a seconda della shell che si sta utilizzando).
Questo è fondamentalmente il modo in cui funziona il reindirizzamento stdout.
Diciamo che non voglio sovrascrivere il mio saluto.txt, c'è un operatore di reindirizzamento anche per questo, >>:
$ echo Salve professor Falken >> saluto.txt
Questo aggiungerà Salve professor Falken alla fine del file saluto.txt, se il file non esiste già lo creerà per noi come ha fatto con l'operatore >.
Hai imparato che puoi usare diversi flussi di stdout , come un file o lo schermo del tuo pc. Bene, ci sono anche diversi flussi standard di input (stdin) che puoi usare. Ci sono stdin da dispositivi come la tastiera, ma possiamo usare file, output da altri processi e anche il terminale
$ cat < joshua.txt > falken.txt
Proprio come abbiamo usato > per il reindirizzamento del stdout, possiamo usare < per il reindirizzamento di stdin.
Normalmente nel comando cat, si invia un file e quel file diventa lo stdin, in questo caso, abbiamo reindirizzato joshua.txt come stdin. Poi l'output di cat joshua.txt viene reindirizzato ad un altro file chiamato falken.txt .
Proviamo qualcosa di diverso, elenchiamo il contenuto di una directory che non esiste sul nostro sistema e reindirizziamo di nuovo l'output al file joshua.txt.
$ ls /mia/directory > joshua.txt
Quello che dovresti vedere è:
ls: cannot access /mia/directory: No such file or directory
Probabilmente stai pensando, ma il messaggio non avrebbe dovuto essere inviato al file? In realtà c'è un altro flusso di I/O chiamato errore standard (stderr). Per impostazione predefinita, stderr invia il suo output anche allo schermo, è un flusso completamente diverso da stdout. Quindi dovrai reindirizzare il suo output in un modo diverso.
Sfortunatamente il reindirizzamento non è semplice come usare < o > ma è similare. In questo caso si utilizzano dei descrittori di file. Un descrittore di file è un numero non negativo che viene utilizzato per accedere a un file. Per ora ti basti sapere che il descrittore di file per stdin, stdout e stderr è rispettivamente 0, 1 e 2.
Quindi ora possiamo reindirizzare lo stderr al file in questo modo:
$ ls /fake/directory 2> joshua.txt
Ora solo i messaggi stderr sono visibili in joshua.txt.
E se volessi vedere sia stderr che stdout nel file joshua.txt? È possibile farlo anche con i descrittori dei file:
$ ls /fake/directory > joshua.txt 2>&1
L'ordine delle operazioni qui è importante, 2>&1 invia stderr a qualsiasi stdout stia indicando. In questo caso stdout sta puntando ad un file, quindi 2>&1 invia anche stderr ad un file. Quindi se si apre quel file dovresti vedere sia stderr che stdout.
C'è un modo più breve per reindirizzare sia stdout che stderr ad un file:
$ ls /fake/directory &> joshua.txt
Ora, cosa succede se voglio sbarazzarmi completamente dei messaggi stderr? Puoi reindirizzare l'output ad /dev/null e questo eliminerà qualsiasi input.
pipe e tee
L'operatore pipe, rappresentato da una barra verticale |, ci permette di ottenere lo stdout di un comando e di farlo passare come stdin ad un altro processo.
$ ls -la /bin | less
E se volessi scrivere l'output del mio comando su due flussi diversi? Questo è possibile con il comando tee:
$ ls | tee joshua.txt
In questo modo dovresti vedere l'output di ls sul tuo schermo e se apri il file vedrai le stesse informazioni.
grep
Il comando grep èil più comune comando di elaborazione del testo che utilizzerai. Consente di cercare nei file i caratteri che corrispondono a un determinato modello.
$ grep fuoco esempio.txt
È possibile anche inserire schemi che non prendono in considerazione le maiuscole e minuscole con il flag -i:
$ grep -i esempio_schema esempiofile
Per essere ancora più flessibile con grep è possibile combinarlo con altri comandi con | (pipe).
$ env | grep -i User
env
Il comando env restituisce un sacco di informazioni sulle variabili ambientali. Queste variabili contengono informazioni utili che la shell e altri processi possono utilizzare.
$ env
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/bin
PWD=/home/user
USER=mario
Per esempio scarichi e si installi manualmente un pacchetto da internet e lo metti in una directory non standard e si vuole eseguire quel comando, si digita $ coolcommand e il prompt dice comando non trovato. Quello che sta succedendo è che la variabile $PATH non controlla quella directory per questo binary, quindi presenta un errore. Puoi semplicemente modificare la variabile PATH per includere quella directory nella tua variabile d'ambiente PATH.
cut
Per spiegare questo comando crea il file falken.txt. Aggiungi uno spazio con TAB, per farlo tieni premuto Ctrl+v+TAB.
$ echo 'Salve sono il professor Falken' > falken.txt
Vediamo quindi il comando cut che estrae una porzione di testo da un file.
$ cut -c 5 falken.txt
Sopra il risultato è "e", la quinta lettera del testo presente nel file. Il flag -c sta per character e il conteggio parte da 1 e da destra.
Per estrarre il contenuto da un campo (field), dovremo fare una piccola modifica, inserire il flag -f:
$ cut -f 2 falken.txt
Il flag -f o field flag taglia il testo in base ai campi, per default usa i TAB come delimitatori, quindi tutto ciò che è separato da un TAB è considerato un campo. Dal file ottengo "Falken".
Si può personalizzare anche il delimitatore di campo in questo modo:
$ cut -f 1 -d " " falken.txt
Infatti sopra il delimitatore, grazie al flag -d, è stato modificato in " ".
paste
Il comando paste (incolla) è simile al comando cat, fonde le linee insieme in un file. Supponiamo di avere un file con il seguente testo all'interno:
Ciao
sono
Mario
Uniamo tutte queste linee in una sola linea.
$ paste -s esempio.txt
Il delimitatore di default per paste è TAB.
Si può cambiare il delimitatore con il flag -d.
$ paste -d ' ' -s esempio.txt
head
Diciamo che abbiamo un file molto lungo e che vuoi vedere solo le prime righe di questo file di testo? Puoi farlo con il comando head, di default il comando head ti mostrerà le prime 10 righe di un file.
$ head /var/log/syslog
Puoi anche modificare il numero delle linee come preferisci...
$ head -n 23 /var/log/syslog
tail
Simile al comando head, il comando tail ti permette di vedere le ultime 10 righe di un file per default.
$ tail /var/log/syslog
Puoi cambiare il numero di righe che vuoi vedere.
$ tail -n 23 /var/log/syslog
Un'altra opzione che puoi usare è il flag -f, questo seguirà il file man mano che cresce.
Il tuo file syslog cambierà continuamente mentre interagisci con il tuo sistema ed usando -f puoi vedere tutto ciò che viene aggiunto al file.
$ tail -f /var/log/syslog
expand and unexpand
Normalmente i TAB mostrano una differenza evidente, ma alcuni file di testo non la mostrano abbastanza bene. Avere i TAB in un file di testo potrebbe non essere la spaziatura desiderata. Per cambiare i TAB in spazi, usa il comando expand.
$ expand esempio.txt
Il comando qui sopra stamperà l'output con ogni TAB convertito in un gruppo di spazi.
Al contrario di expand, possiamo riconvertire ogni gruppo di spazi in un TAB con il comando unexpand:
$ unexpand -a esempio.txt
join and split
Il comando join permette di unire più file in base ad un campo comune:
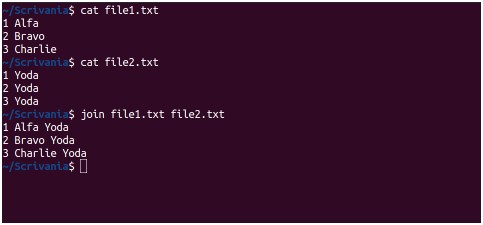
I file sono uniti dal primo campo per default ed i campi devono essere identici, se non lo sono puoi ordinarli, quindi in questo caso i file sono uniti tramite 1, 2, 3.
Puoi anche dividere un file in diversi file con il comando split:
$ split unfile
Questo lo dividerà in diversi file, di default li dividerà una volta raggiunto il limite di 1000 linee. I file si chiamano x** per impostazione predefinita.
sort
Il comando sort è utilizzato per ordinare degli elementi, delle linee di testo.
file1.txt
banana
ananas
kiwi
mela
cocomero
$ sort file1.txt
ananas
banana
cocomero
kiwi
mela
Aggiungendo il flag -r puoi ottenere l'ordine inverso.
$ sort -r file1.txt
tr
Il comando tr consente di trasformare un insieme di caratteri in un altro insieme di caratteri. Proviamo ad esempio a cambiare tutti i caratteri minuscoli in caratteri maiuscoli.
$ tr a-z A-Z
joshua
JOSHUA
uniq
Il comando uniq è un altro strumento utile per l'analisi del testo.
Supponiamo di avere il seguente testo in un file:
banana
banana
falken
falken
pera
pera
cravatta
Vuoi rimuovere i duplicati? Usa il comando uniq:
$ uniq nomefile.txt
Il risultato sarà:
banana
falken
pera
cravatta
Puoi anche ottenere il conteggio delle parole presenti utilizzando il flag -c:
$ uniq -c nomefile.txt
Ottieni:
2 banana
2 falken
2 pera
1 cravatta
Se invece vuoi ottenere solo chi non ha duplicati, l'unicità, utilizza il flag -u:
$ uniq -u nomefile.txt
Ed ottieni...
cravatta
Il limite di uniq è che per operare i duplicati devono essere adiacenti, uno dopo l'altro, quindi prima devi ordinare il tutto con il comando sort.
wc
Il comando wc mostra il conteggio totale delle parole in un file.
$ wc nomefile.txt
24
Per vedere solo il conteggio di un certo campo puoi usare rispettivamente i flag -l, -w o -c.
Un altro comando che si può usare per fare il conteggio delle righe di un file è il comando nl.
$ nl nomefile.txt
In questo modo ottieni:
1. banana
2. falken
3. pera
4. cravatta